 This is a follow-on from “RealTime Offer Management” (RTOM) series of posts, the first of which can be found here. A complete list of articles in this series is included at the bottom of this post.
This is a follow-on from “RealTime Offer Management” (RTOM) series of posts, the first of which can be found here. A complete list of articles in this series is included at the bottom of this post.
When first visualising the RTOM Application I spent a lot of time thinking about how a user could define rules that would allow the RTOM processing to;
- Filter inputs to Data-Nodes from Event Data
- Allow conditions to turn-on-off Data Node Switches
- Compute Data-Node values from other Data-Nodes
- Evaluate whether an Offer should be made
- Evaluate the rewards to be made within the offer based on patron’s profile and/or other information managed by RTOM
- Allow the reward discounts/values to be calculated from RTOM data
- Allow decision criteria to be flexible based on Events, Data-Nodes and/or Patron Attributes
I did not want to build a fully fledged rules language to rival a commercial product, but rather wanted to focus on a subset of rules that would merge seamlessly into a dedicated realtime offer management application.
In its simplest form the Rules Language required a very small number of statements that are divided into two classes, conditionals and calculators;
- IF
- AND-IF
- SWITCH-ON-IF
- SWITCH-OFF-IF
- GET (Calculate)
In its simplest form a conditional statement would look like
if operand evaluation operand
and a calculation statement would look like
get operand calc_symbol operand
So far seems simple enough, however the beast known as complexity reared its head when I added in the “Operand Types” and “Operand Qualifiers” the Rules Language was requried to evaluate.
Each “operand” can be one of the following types;
- Value, Number, Percentage
- Keyword (reserved word to denote a language function. e.g. #mon, #tue, #str_month, etc)
- Quick List (name of a list that contains a set of items to be evaluated)
- Array
- Objects (Event, Data-Node, Offer)
- Meta Data (attached to Event, Data-Node, Offer)
- Data (from Event, Node)
- Function
Note – The Array and Quick List types can be a list of any of the other operand types with the exception of the Function type.
In addition to the range of operand types there was an added element of complexity with “scope of data” for Event, Data-Node and Offer types and Operand Qualifiers to allow manipulation of results.
My goal was to build a rules language that met the above requirements and do it in a way that;
- Allowed dynamic configuration data driven processing to be used for managing the simplest through to the most complex statement types with the scope defined above
- The language and processing solution had to be flexible in that I could add new features easily with minimal to no coding on the syntax checkers and parsers
To put this goal in context, an example of a complex conditional statement would be;
if count { f&b_payment
where-log e.~business = @fine_dining
and e.total_bill > 100
and e.~date > #str_year()
and e.~date > o.~date
group-by [~business]
group-drop count < 2
}
=> match p.loyalty_tier
with "platinum" = 3 | "gold" = 5 default 7
and-if o~date < #today(-120)
The syntax breakdown is
if count of
{ read through the f&b_payment events
select events (e) based on the following criteria
e.~business - is in list of fine dining establishments
e.total_bill - was over 100
e.~date - since the start of the year
e.~date - since the last time this offer was made
group the results by business
drop any groups with less than 2 entries }
is greater than or equal
3 for "platinum" members
5 for "golds members"
7 for everyone else
and if this offer has not already been made in the last 120 days
As you can see this is a cross between logic statements and SQL. style statements.
The biggest concession I made to my original vision was to accept that a Rules Language needs some structure and will not be in prose style English. I am sure with enough time I could get to a version that would be close to the breakdown above but I have decided to forego this level of language verbosity and stick to a midway point in order to get the solution completed. At some later point I will evaluate how much further the syntax needs to evolve to be prose based rather than condition/function based.
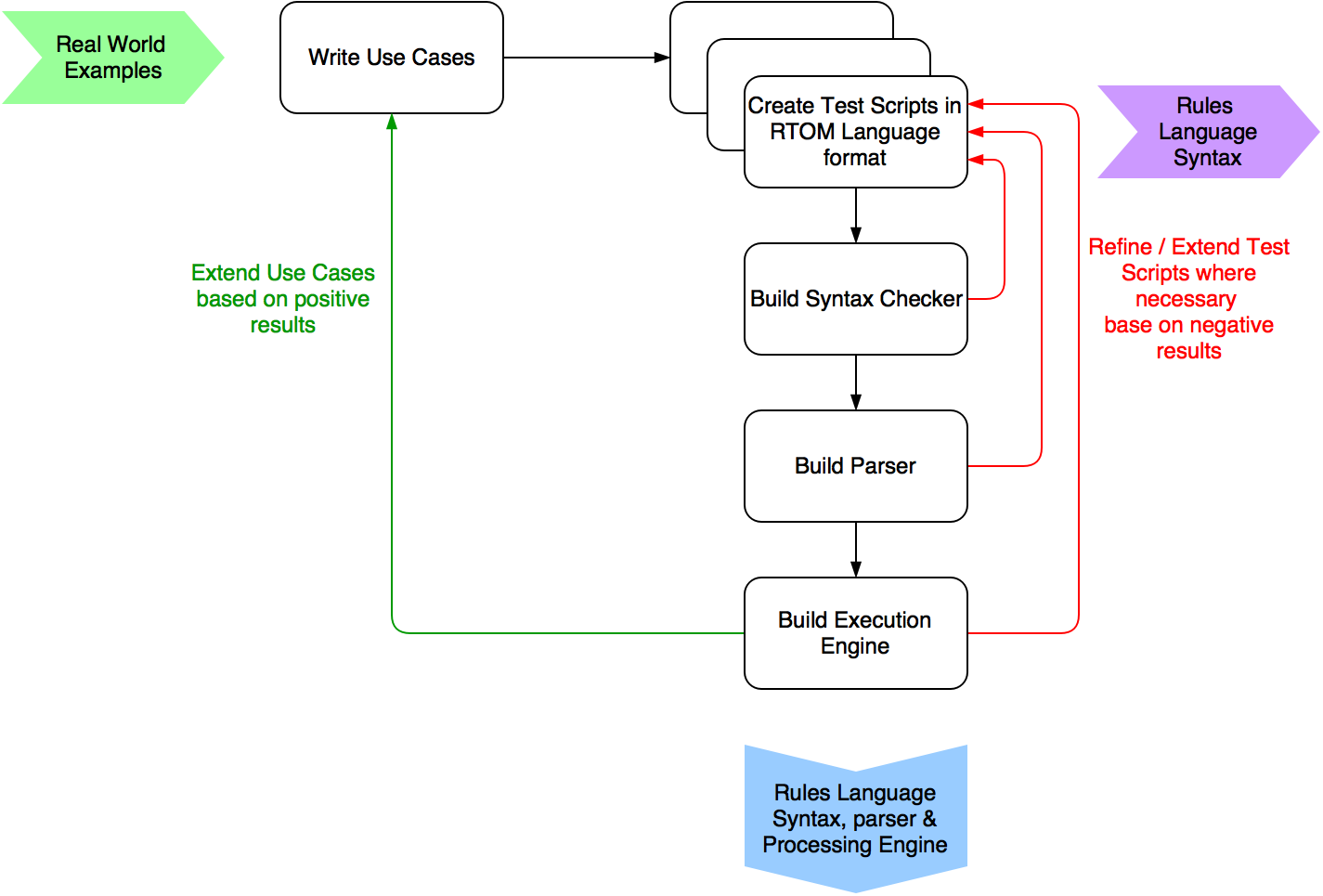
So on to how to build a Rules language. What follows is my approach to building what I needed for the RTOM application. It is by no means a definitive statement of “this is how it is done” it is just one approach that worked for me.
Early on I discovered that trying to define a full syntax of a language up front was extremely difficult to achieve. I therefore adopted an iterative Test Driven approach where the Rules Language Syntax evolved from the Test Scripts;
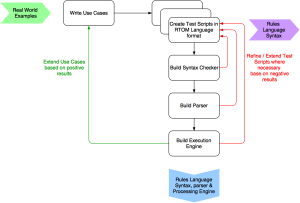
As well as using the iterative test driven approach I also adopted a “full-on refactoring” mindset to the code development. No addition/modification to working code was too big or small in order to make the code-base more flexible and deliver a smaller footprint. The coding principles I used were in summary;
- Test Driven Development
- Data Driven Engine
- Single Function Design
- Iterative approach
- Refactor as a Principle
- Configuration over Coding
- No hardcoding
There were three main pieces of code to be built for the rule language. A Syntax Checker to validate the input, a Parser to transform the raw input into executable structure and the Execution Engine to process the rules language.
THE SYNTAX CHECKER
This was actually the most challenging piece of code to write. It would have been easy to have just built a massive set of ‘if’ based coding conditions but that would have detracted from the goals mentioned earlier in this post and the coding approach I wanted to use. The syntax checker evolved to perform four distinct functions, each one layered on top of the other as the rules passed through their area of focus.
The first step was to “standardise” the input from the user. In order to build repeatable consistent syntax checking functionality the easiest way to drive the functionality is to ensure consistency in the input. Rather than push strict formatting rules back to the user, the system first tries to standardise the inputs. I decided on an approach of formatting whereby each distinct piece of the rule would be separated by a single space and all unnecessary whitespace would be removed.
// Step 1 - Standardise the Input
if event.~business = ["abc", "def", "xyz"]
--> if event.~business = ["abc","def","xyz"]
if sum{event.value where-log e.~business = @fine_dine} > 200
--> if sum { event.value where-log e.~business = @fine_dine } > 200
The second step was to “categorise” each piece of the rule within one of the standard allowed categories.
// Step 2 - Categorisation of function pieces
if event.~business = ["abc","def","xyz"]
--> if statement
event.~business event-meta
= eval
["abc","def","xyz"] array
if sum { event.value where-log e.~business = @fine_dine } > 200
--> if statement
sum function
{ func-start
event.value event-data
where-log qualifier
e.~business event-meta
= eval
@fine_dine qlist
} func-end
> eval
200 number
The third step involves “pattern matching” to check the structure of the rule was correct. This was looking to be one of the most tricky parts of the syntax checking until I remembered a design pattern I used back in 2003 to construct an automated XSLT generator. It involves breaking the allowed structure into a set of simple definitions defined by configuration data that drives a recursive OO based process for pattern checking and verification. The actual code to do the pattern checking is less than 80 lines and relies on a pattern checking data structure to tell it what is valid. The premise of the processing is to check through all viable patterns until a match is found. As this processing happens during data input by the user a small sub-second time lag is of no issue.
The pattern checking definition looks as follows (note sample only);
$parse_patterns = [
'start' => [
'#1' => ['statement', '__cond', '__and-if'],
'#2' => ['statement.get', '__get'],
'#3' => ['statement', '__cond'],
'#6' => ...
],
'__and-if' => [
'#1' => ['statement.and-if', '__cond', '__and-if'],
'#2' => ['statement.and-if', '__cond']
],
'__cond' => [
'#1' => ['__lhs', 'eval', '__rhs'],
'#2' => ['__function', 'eval', '__rhs'],
'#3' => ...
],
As you can see the patterns are described using the “categories” from step 2. The pattern checking object takes the “start” input pattern and tries to find a match within its valid pattern model stepping through each option. It steps through each option until it either runs out or finds a valid pattern. The “__” prefixed names are used to break the pattern model into “sub-patterns” which can be put together in different ways. By doing this there is no need to try and define each unique instance of all possible patterns (an impossible task).
When a “sub-pattern” identifier is found the pattern checking object instantiates a new version of itself and passes the child object the “formula categories”, “starting point” and “sub-pattern” it is to focus on. Child objects can also instantiate other child objects. Hence we have a recursive approach that requires no coding to specifically refer to formula categories and valid patterns. The codes only job is to compare the formula categories with the valid data patterns it has. This allowsteh rules language to be extended without significant coding effort. Also the sub-patterns can be recursively called from within themselves (e.g. “and-if”).
I also built in the capability for the categories to be qualified using a dot “.” notation to provide flexibility for checking for specific category element types in particular locations in the rule syntax.
'__function' => [
'#1' => ...
'#2' => ...
'#3' => ['function.[sum,count,maximum,minimum,average]',
'func-start', ['event', 'event-data', 'node'],
'qualifier.where-log', '__log', 'func-end'],
'#4' => ...
],
The fourth step is “context checking“. In this step the processing iterates through the categories and ensure the contents of each category are suitable for the processing to be performed. For example all elements in an array are the same type, all elements in an array are of the type required, a number is compared to a number, etc.
THE PARSER
Once you have a valid input rule format the next step is to convert it to an “executable format”. The purpose of this step is to build a structured representation of the rule which can be easily interpreted and executed by the “rule execution engine”. Think of it as pseudo “code compilation”. Within the RTOM the rules input by the user are always stored in the exact format they were keyed in (think source) and a second version in execution format. As the execution format is not actually “executable code” but rather formalised rules to drive a “generic execution engine”, I opted to store the “code” in JSON format for ease of processing. Taking our earlier examples the executable formats would look as follows;
if event.~business = ["abc","def","xyz"]
--> { statement: "if",
lhs: { type: "event-meta",
operand: "event.~business", }
eval: "=",
rhs: { type: "array",
operand: [ "abc", "def", "xyz" ] }
}
if sum { event.value where-log e.~business = @fine_dine } > 200
--> { statement: "if",
lhs: { type: "function",
function: { name: "sum",
input-type: "event-data",
where-log: [
{ lhs: { type: "event-meta",
operand: "e.~business" }
eval: "=",
rhs: { type: "qlist",
operand: "@fine_dine" }
} ]
}
}
eval: ">",
rhs: { type: "number",
operand: 200 }
}
THE RULES EXECUTION ENGINE
The rules execution engine (REE) is in itself a simple object that consists of a discrete set of functions (methods) that do one and only one thing. This “single function” approach allowed me to build fairly bullet proof code that can be “welded together” in various ways based on an input that is variable in structure (i.e. the Rule). The REE takes that JSON structure and reads through it looking for specific element structures and handing them off to the aforementioned functions. An object containing the relevant formatting functions and value is is created for each operand. The execution engine operates as follows;
- Determine the rule style to be processed (Condition or Calculation) from the statement element
- Resolve the value of each operand based on its type
- For quick list types get the array of items references
- Pre-process specific #keyword instructions
- Resolve all #keyword values (e.g. #mon = 1, #thu = 4, #str_month() = 2016-12-01, etc)
- Perform statement processing using functions on the operand objects
- Return the result. True/False for conditions and Value for calculations
——–
So in summary, the rules language and its associated processing has been quite a challenge to complete and the version of the code I have now is v3. . While there is room for expanding the range of statement types and enhancing the existing facilities I think the way I have approached the build has set a reasonably good foundation for futher growth. The language format I have settled on (for now) is a bit more “codified” in structure than was my original ambition but is generally as readable as SQL. As the RTOM application matures I will focus on taking the language to a more descriptive form and losing the “code” feel to it. In total the three parts of the solution Syntax Checker, Parser, Execution Engine have a footprint of just under 2000 lines of code which is (I think) pretty good for the level of flexibility it provides in its current state.
One of the fun aspects about designing and building this type of solution and approaching it in the manner described above is that the true range of flexibility only became apparent when I started showing it to people who asked “can it do this …”, and realising it is flexibile enough to accommodate the request even though I had not specifically designed for it.
In the next articles I will describe how the Offers are structured and the facilities the RTOM provides in this area.
Complete list of articles in series;














 This is a follow-on from “RealTime Offer Management” (RTOM) post published on 19th November 2016 which can be found
This is a follow-on from “RealTime Offer Management” (RTOM) post published on 19th November 2016 which can be found